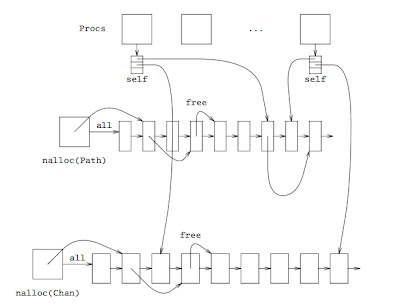
To measure the impact of the different changes in the
behavior of the system, we took the final system and run it
with diagnostic output enabled for page allocation and page
faults, and measured the different events of interest. Then
we did the same disabling one or more of the improvements.
The results are not fully precise because debugging output
may miss some events sometimes. Further evaluation will use
counters instead, and compare with a stock Plan 9 system.
We have to say that the impact of the changes is more
dramatic than shown by the results, because early modifica-
tions for the mount driver and other parts of the system, on
their own, do a good job reducing the impact of system load
(e.g., by better caching).
The variations of the system executed are given these
names in the results:
all
The standard Nix mark IV. All new features are in.
nopf
Prefaulting code for text and stack segments is dis-
abled. Such code installs into the MMU entries for
those pages already present in the segments (because of
the cache or other optimizations). The alternative is
installing entries on demand.
flush
Prefaulting code is disabled and the MMU is flushed on
forks, as it is customary on Plan 9. The alternative to
MMU flushes is flushing just the entries for the data
segment (others do not have to be because of optimiza-
tions explained before).
nodeep
Deep stack forks are disabled. Deep stack forks imply
copying the actual stack memory during forks. The
alternative is the standard copy on reference to fork a
stack segment.
nostk
Stack segments are not cached (their memory is not kept
and recycled) and deep stack copies are not performed.
The alternative is the standard construction by zero-
fill on demand (due to page faults) and full dealloca-
tion and allocation of stacks when processes exit and
are created.
none
There are no prefaulting code, the MMU is flushed on
forks, deep stack copying is disabled, and stack memory
is not cached. Quite similar to the state of the system
before any modification was made, but for using 16KiB
pages for user segments.
none4k
This is the old system. Like the previous variation,
but using standard 4KiB pages for user segments.
The system booted normally from a remote file server to exe-
cute a shell instead of the full standard start script, and
then we executed pwd twice. The first table reports the
results for the second run of pwd, counting since we typed
the command to the time when the shell printed its prompt
after pwd completed. The first way to read the table is to
compare any row with the first or the last one, to see the
impact of a particular configuration.
The second table shows the same counters but for the
entire execution of the system, from a hardware reset to the
prompt after executing pwd twice.
_________________________________________________________________________
bench page allocs page frees mmu faults page faults page-ins
_________________________________________________________________________
all 6 5 14 11 1
_________________________________________________________________________
nopf 6 5 16 12 1
_________________________________________________________________________
flush 6 5 22 18 1
_________________________________________________________________________
nodeep 6 6 17 12 1
_________________________________________________________________________
nostk 6 7 16 15 1
_________________________________________________________________________
none 8 8 24 17 1
_________________________________________________________________________
none4k 15 15 65 68 1
_________________________________________________________________________
Page allocations, page deallocations, page faults, MMU
faults, and pages paged in for variations of the system on
the second execution of a simple command.
_________________________________________________________________________
bench page allocs page frees mmu faults page faults page-ins
_________________________________________________________________________
all 229 41 219 210 107
_________________________________________________________________________
nopf 231 41 246 232 109
_________________________________________________________________________
flush 224 38 311 283 109
_________________________________________________________________________
nodeep 227 41 244 237 109
_________________________________________________________________________
nostk 232 56 245 233 109
_________________________________________________________________________
none 236 60 321 296 109
_________________________________________________________________________
none4k 501 107 847 843 313
_________________________________________________________________________
Page allocations, page deallocations, page faults, MMU
faults, and pages paged in for variations of the system for
an entire boot and two executions of a simple command.
Several things can be seen:
∙ going from the old to the new system means going from
68 down to 11 page faults, just for running pwd from
the shell. For the entire boot process it means going
from 843 down to 210.
∙ Using a more reasonable page size, without other opti-
mizations, reduces a lot the number of page faults (as
could be expected). We saw that almost all the 4K pages
paged in are actually used for 16K pages, thus it pays
to change the page size. Also, the new page size has a
significant impact in the size of reads performed by
the mount driver, because it enables concurrent reads
for larger sizes.
∙ Deep stack copying reduces a little the page faults in
the system, but it might not be worth if the time taken
to zero out the stack pages kept in the cache is wasted
when they are not used. In our system that does not
seem to be case.
∙ More efforts should be taken to avoid flushing MMU
state. As it could be expected, not flushing the MMU
when it is not necessary reduces quite a bit the number
of page faults.
As a reference, here we list the trace output for the
old and the new system for executing pwd the second time.
It is illustrative to compare them.
This is for the new system:
% pwd
newpg 0x000000003fe44000 pgsz 0x4000 for 0x4000
fault pid 23 0x20f9e0 r
fault pid 21 0x400000 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20c000 pg 0x1174000 r1 n1
fixfixfault faulted pid 23 s /bin/rc Text 0x200000 addr 0x20c000 pg 0x1174000 ref 1
fault pid 23 0x20a9d9 r
pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x400000 pg 0x3fe6c000 r2 n1
newpg 0x000000003fe80000 pgsz 0x4000 for 0x4000
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x400000 pg 0x3fe80000 ref 1
fault pid 21 0x404b30 w
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x208000 pfixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x404000 pg 0x3fe70000 r2 n1
newpg 0x000000003fe84000 pgsz 0x4000 for 0x4000
g 0x11a4000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x404000 pg 0x3fe84000 ref 1
fault pid 21 0x409afc r
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x208000 pg 0x11a4000 ref 1
fault pid 23 0x400060 w
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x408000 pg 0x3fe78000 r2 n1
newpg 0x000000003fe88000 pgsz 0x4000 for 0x4000
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x408000 pg 0x3fe88000 ref 1
fault pid 21 0x40c178 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x400000 pg 0x3fe6c000 r1 n1
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x400000 pg 0x3fe6c000 ref 1
fault pid 23 0x202aec r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x40c000 pg 0x3fe74000 r2 n1
newpg 0x000000003feaddr 0x200000 pg 0x10e4000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x200000 pg 0x10e4000 ref 1
fault pid 23 0x40a698 r
8c000 pgsz 0x4000 for 0x4000
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x40c000 pg 0x3fe8c000 ref 1
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x408000 pg 0x3fe78000 r1 n1
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x408000 pg 0x3fe78000 ref 1
fault pid 23 0x212b47 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x210000 pg 0x11a8000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x210000 pg 0x11a8000 ref 1
fault pid 23 0x404b30 w
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x404000 pg 0x3fe70000 r1 n1
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x404000 pg 0x3fe70000 ref 1
fault pid 23 0x40c17c r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x40c000 pg 0x3fe74000 r1 n1
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x40c000 pg 0x3fe74000 ref 1
fault pid 23 0x7ffffeffbfe0 w
fixfault pid 23 s '' sref 1 Stack 0x7ffffdffc000 addr 0x7ffffeff8000 pg 0x3fe60000 r1 n1
fixfaulted pid 23 s '' Stack 0x7ffffdffc000 addr 0x7ffffeff8000 pg 0x3fe60000 ref 1
pgfree pg 0x3fe6c000
pgfree pg 0x3fe70000
pgfree pg 0x3fe78000
pgfree pg 0x3fe74000
fault pid 23 0x400018 w
fixfault pid 23 s /bin/pwd sref 1 Data 0x400000 addr 0x400000 pg 0x0 r0 n-1
pagein pid 23 s 0x400000 addr 0x400000 soff 0x0
newpg 0x000000003fe74000 pgsz 0x4000 for 0x4000
fixfaulted pid 23 s /bin/pwd Data 0x400000 addr 0x400000 pg 0x3fe74000 ref 1
/usr/nemo
pgfree pg 0x3fe74000
And this is for the old system:
fault pid 21 0x2000c4 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x200000 pg 0x116c000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x200000 pg 0x116c000 ref 1
fault pid 21 0x20170a r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x201000 pg 0x116f000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x201000 pg 0x116f000 ref 1
fault pid 21 0x205dfc r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x205000 pg 0x1132000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x205000 pg 0x1132000 ref 1
fault pid 21 0x40b834 w
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x40b000 pg 0x11b3000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x40b000 pg 0x11b3000 ref 1
fault pid 21 0x407c78 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x407000 pg 0x11ac000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x407000 pg 0x11ac000 ref 1
fault pid 23 0x20f9e0 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20f000 pg 0x1138000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20f000 pg 0x1138000 ref 1
fault pid 23 0x7fffffffefe8 w
fixfault pid 23 s /bin/rc sref 1 Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11b0000 r2 n1
newpg 0x00000000011d2000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s '' Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11d2000 ref 1
fault pid 23 0x20a9d9 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20a000 pg 0x1146000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20a000 pg 0x1146000 ref 1
fault pid 23 0x20be91 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20b000 pg 0x1135000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20b000 pg 0x1135000 ref 1
fault pid 23 0x400060 w
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x400000 pg 0x11aa000 r2 n1
newpg 0x00000000011d0000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x400000 pg 0x11d0000 ref 1
fault pid 23 0x202aec r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x202000 pg 0x1130000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x202000 pg 0x1130000 ref 1
fault pid 23 0x40a698 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x40a000 pg 0x119e000 r2 n1
newpg 0x00000000011d6000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x40a000 pg 0x11d6000 ref 1
fault pid 23 0x20977d r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x209000 pg 0x1139000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x209000 pg 0x1139000 ref 1
fault pid 23 0x20dbe3 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20d000 pg 0x113b000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20d000 pg 0x113b000 ref 1
fault pid 23 0x212b47 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x212000 pg 0x113c000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x212000 pg 0x113c000 ref 1
fault pid 23 0x401338 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x401000 pg 0x11af000 r2 n1
newpg 0x00000000011ce000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x401000 pg 0x11ce000 ref 1
fault pid 23 0x210670 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x210000 pg 0x113d000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x210000 pg 0x113d000 ref 1
fault pid 23 0x404b30 w
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x404000 pg 0x11ae000 r2 n1
newpg 0x00000000011d3000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x404000 pg 0x11d3000 ref 1
fault pid 23 0x21107c r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x211000 pg 0x1143000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x211000 pg 0x1143000 ref 1
fault pid 23 0x40c17c r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x40c000 pg 0x11b2000 r2 n1
newpg 0x00000000011cf000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x40c000 pg 0x11cf000 ref 1
fault pid 23 0x4097fc r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x409000 pg 0x1196000 r2 n1
newpg 0x00000000011ca000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x409000 pg 0x11ca000 ref 1
fault pid 23 0x20e02d r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20e000 pg 0x1147000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20e000 pg 0x1147000 ref 1
fault pid 23 0x20cbb0 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x20c000 pg 0x1129000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x20c000 pg 0x1129000 ref 1
fault pid 23 0x40204a r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x402000 pg 0x11a7000 r2 n1
newpg 0x00000000011c6000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x402000 pg 0x11c6000 ref 1
fault pid 23 0x2086dc r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x208000 pg 0x1165000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x208000 pg 0x1165000 ref 1
fault pid 23 0x213000 r
fixfault pid 23 s /bin/rc sref 9 Text 0x200000 addr 0x213000 pg 0x1142000 r1 n1
fixfaulted pid 23 s /bin/rc Text 0x200000 addr 0x213000 pg 0x1142000 ref 1
fault pid 23 0x4055b8 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x405000 pg 0x11a9000 r2 n1
newpg 0x00000000011d8000 pgsz 0x4000 for 0x1000
splitbundle pg 0x00000000011d8000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x405000 pg 0x11d8000 ref 1
fault pid 23 0x4081a8 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x408000 pg 0x11a8000 r2 n1
newpg 0x00000000011db000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x408000 pg 0x11db000 ref 1
fault pid 23 0x407c78 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x407000 pg 0x11ac000 r2 n1
newpg 0x00000000011da000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x407000 pg 0x11da000 ref 1
fault pid 23 0x406dd8 r
fixfault pid 23 s /bin/rc sref 1 Data 0x400000 addr 0x406000 pg 0x11ad000 r2 n1
newpg 0x00000000011d9000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/rc Data 0x400000 addr 0x406000 pg 0x11d9000 ref 1
fault pid 21 0x7fffffffefe8 w
fixfault pid 23 0x7ffffeffefe0 w
fixfault pid 23 s '' sref 1 Stack 0x7ffffdfff000 addr 0x7ffffeffe000 pg 0x0 r0 n-1
newpg 0x00000000011dc000 pgsz 0x4000 for 0x1000
splitbundle pg 0x00000000011dc000
fixfaulted pid 23 s '' Stack 0x7ffffdfff000 addr 0x7ffffeffe000 pg 0x11dc000 ref 1
pgfree pg 0x11d2000
pgfree pg 0x11d0000
pgfree pg 0x11ce000
pgfree pg 0x11c6000
pgfree pg 0x11d3000
pgfree pg 0x11d8000
pgfree pg 0x11d9000
pgfree pg 0x11da000
pgfree pg 0x11db000
pgfree pg 0x11ca000
pgfree pg 0x11d6000
pgfree pg 0x11cf000
faultfault pid 23 0x7fffffffef98 w
fixfault pid 23 s /bin/pwd sref 1 Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11dc000 r1 n1
fixfaulted pid 23 s '' Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11dc000 ref 1
fault pid 23 0x20008a r
fixfault pid 23 s /bin/pwd sref 3 Text 0x200000 addr 0x200000 pg 0x11cd000 r1 n1
fixfaulted pid 23 s /bin/pwd Text 0x200000 addr 0x200000 pg 0x11cd000 ref 1
fault pid 23 0x400018 w
fixfault pid 23 s /bin/pwd sref 1 Data 0x400000 addr 0x400000 pg 0x0 r0 n-1
pagein pid 23 s 0x400000 addr 0x400000 soff 0x0
newpg 0x00000000011cf000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/pwd Data 0x400000 addr 0x400000 pg 0x11cf000 ref 1
fault pid 23 0x201b6d r
fixfault pid 23 s /bin/pwd sref 3 Text 0x200000 addr 0x201000 pg 0x11d1000 r1 n1
fixfaulted pid 23 s /bin/pwd Text 0x200000 addr 0x201000 pg 0x11d1000 ref 1
pid 21 s /bfault pid 23 0x2020ef r
fixfault pid 23 s /bin/pwd sref 3 Text 0x200000 addr 0x202000 pg 0x11d4000 r1 n1
fixfaulted pid 23 s /bin/pwd Text 0x200000 addr 0x202000 pg 0x11d4000 ref 1
fault pid 23 0x2040b2 r
fixfault pid 23 s /bin/pwd sref 3 Text 0x200000 addr 0x204000 pg 0x11d7000 r1 n1
fixfaulted pid 23 s /bin/pwd Text 0x200000 addr 0x204000 pg 0x11d7000 ref 1
/usr/nemo
fault pid 23 0x401098 r
fixfault pid 23 s /bin/pwd sref 1 Data 0x400000 addr 0x401000 pg 0x0 r0 n-1
pagein: zfod 0x401000
newpg 0x00000000011d6000 pgsz 0x1000 for 0x1000
fixfaulted pid 23 s /bin/pwd Data 0x400000 addr 0x401000 pg 0x11d6000 ref 1
pgfree pg 0x11dc000
pgfree pg 0x11cf000
pgfree pg 0x11d6000
in/rc sref 1 Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11b0000 r1 n1
fixfaulted pid 21 s '' Stack 0x7ffffefff000 addr 0x7fffffffe000 pg 0x11b0000 ref 1
fault pid 21 0x20f9e0 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20f000 pg 0x1138000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20f000 pg 0x1138000 ref 1
fault pid 21 0x20a9d9 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20a000 pg 0x1146000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20a000 pg 0x1146000 ref 1
fault pid 21 0x20bdca r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20b000 pg 0x1135000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20b000 pg 0x1135000 ref 1
fault pid 21 0x400000 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x400000 pg 0x11aa000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x400000 pg 0x11aa000 ref 1
fault pid 21 0x20ddb3 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20d000 pg 0x113b000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20d000 pg 0x113b000 ref 1
fault pid 21 0x212ea2 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x212000 pg 0x113c000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x212000 pg 0x113c000 ref 1
fault pid 21 0x401338 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x401000 pg 0x11af000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x401000 pg 0x11af000 ref 1
fault pid 21 0x210670 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x210000 pg 0x113d000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x210000 pg 0x113d000 ref 1
fault pid 21 0x404b30 w
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x404000 pg 0x11ae000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x404000 pg 0x11ae000 ref 1
fault pid 21 0x409afc r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x409000 pg 0x1196000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x409000 pg 0x1196000 ref 1
fault pid 21 0x211ba3 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x211000 pg 0x1143000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x211000 pg 0x1143000 ref 1
fault pid 21 0x20e02d r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20e000 pg 0x1147000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20e000 pg 0x1147000 ref 1
fault pid 21 0x208574 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x208000 pg 0x1165000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x208000 pg 0x1165000 ref 1
fault pid 21 0x202c39 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x202000 pg 0x1130000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x202000 pg 0x1130000 ref 1
fault pid 21 0x40a698 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x40a000 pg 0x119e000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x40a000 pg 0x119e000 ref 1
fault pid 21 0x2097b7 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x209000 pg 0x1139000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x209000 pg 0x1139000 ref 1
fault pid 21 0x213000 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x213000 pg 0x1142000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x213000 pg 0x1142000 ref 1
fault pid 21 0x40c178 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x40c000 pg 0x11b2000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x40c000 pg 0x11b2000 ref 1
fault pid 21 0x20ce7e r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x20c000 pg 0x1129000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x20c000 pg 0x1129000 ref 1
fault pid 21 0x204bba r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x204000 pg 0x1133000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x204000 pg 0x1133000 ref 1
fault pid 21 0x402611 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x402000 pg 0x11a7000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x402000 pg 0x11a7000 ref 1
fault pid 21 0x405e00 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x405000 pg 0x11a9000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x405000 pg 0x11a9000 ref 1
fault pid 21 0x408d48 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x408000 pg 0x11a8000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x408000 pg 0x11a8000 ref 1
fault pid 21 0x20310e r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x203000 pg 0x1136000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x203000 pg 0x1136000 ref 1
fault pid 21 0x40b834 w
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x40b000 pg 0x11b3000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x40b000 pg 0x11b3000 ref 1
fault pid 21 0x206ab9 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x206000 pg 0x113a000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x206000 pg 0x113a000 ref 1
fault pid 21 0x406820 r
fixfault pid 21 s /bin/rc sref 1 Data 0x400000 addr 0x406000 pg 0x11ad000 r1 n1
fixfaulted pid 21 s /bin/rc Data 0x400000 addr 0x406000 pg 0x11ad000 ref 1
fault pid 21 0x7fffffffce78 w
fixfault pid 21 s /bin/rc sref 1 Stack 0x7ffffefff000 addr 0x7fffffffc000 pg 0x11bd000 r1 n1
fixfaulted pid 21 s '' Stack 0x7ffffefff000 addr 0x7fffffffc000 pg 0x11bd000 ref 1
fault pid 21 0x2071d8 r
fixfault pid 21 s /bin/rc sref 7 Text 0x200000 addr 0x207000 pg 0x116b000 r1 n1
fixfaulted pid 21 s /bin/rc Text 0x200000 addr 0x207000 pg 0x116b000 ref 1