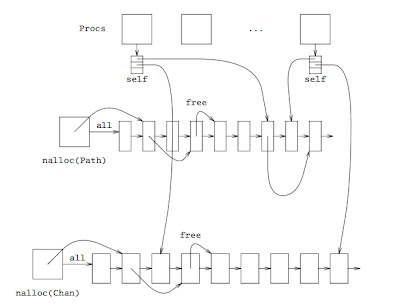
We made an experiment, running a program that spawns as many compiler processes as needed to compile the kernel source files in parallel. This uses the new AMP scheduler, where core 0 assigns processes to other cores for execution.
To see the effect of NUMA in the 32 core machine used for testing, we timed this program for all number of cores: first, allocating memory from the domain local to the process; second, allocating it always from the last memory domain.
Thus, if NUMA effects are significant, it must show up in the plot. This is it:
For less than 5 cores there is a visible difference. Using a NUMA aware allocator results in lower times, as it could be expected. However, for more cores there is no significant difference, which means that NUMA effects are irrelevant on this system and this load (actually, the NUMA allocator is a little bit worse).
The probable reason is that when using more cores the system seems to tradeoff load-balancing of processes among cores and memory locality. Although all memory is allocated from the right color, the pages kept in the cache already have a color, as does kernel memory. Using processors from other colors comes at the expense of using remote memory, which means that in the end it does not matter much where do you allocate memory.
If each process relied on a different binary, results might be different. However, in practice, the same few binaries are used most of the time (the shell, common file tools, compilers, etc.).
Thus, is NUMA still relevant for this kind of machine and workload?
As provocative as this question might be...